Transaction Enrichment API: The Complete Guide for Fintech Developers

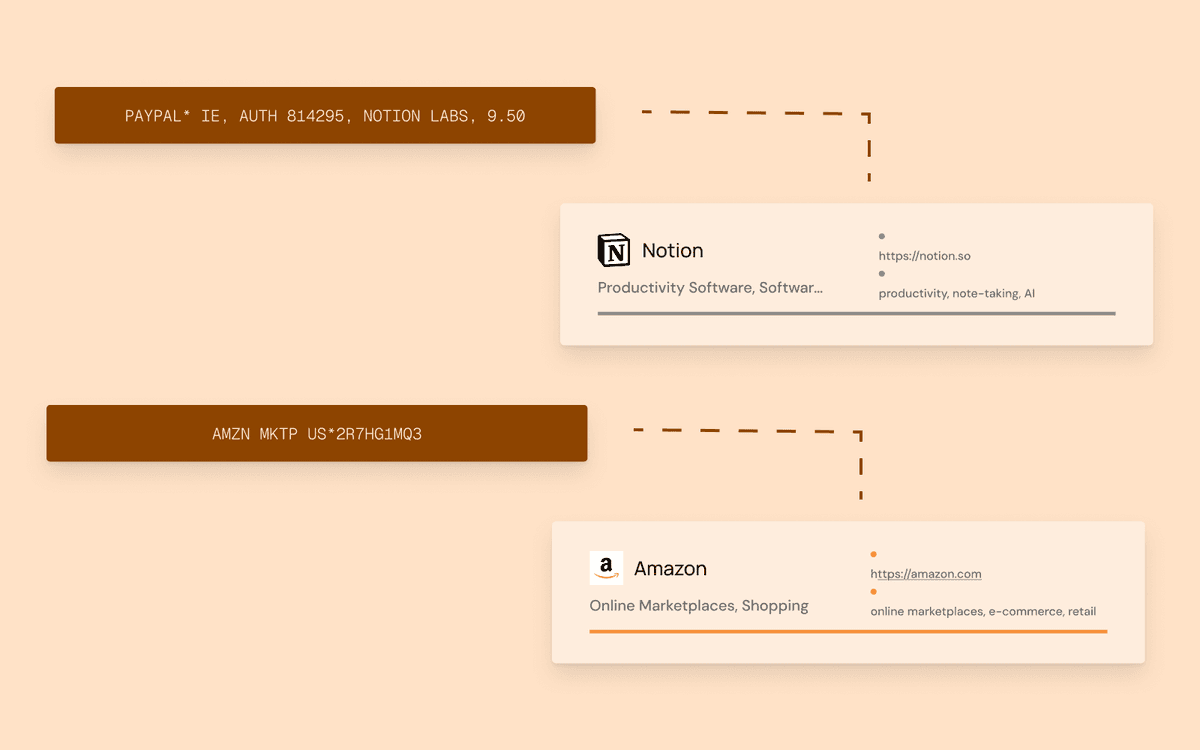
Raw bank transactions are one of the most common sources of friction in fintech products. They arrive as cryptic strings like AMZN MKTP US*2R7HG1MQ3 or SQ *VERVE COFFEE ROASTERS, vary wildly between banks and countries, and rarely include useful context about the merchant, category, or location. For developers building financial applications, this messy data makes it nearly impossible to deliver accurate spending insights, or budgeting tools without significant processing.
A transaction enrichment API solves this problem by transforming raw transaction data into structured, human-readable, and machine-usable information. Instead of building complex parsing systems in-house, fintech teams send raw transaction strings to an API and receive clean merchant names, accurate categories, brand logos, geographic data, and confidence scores in return.
This guide covers everything developers need to know about transaction enrichment APIs: what they are, how they work, why the problem is so difficult, what to look for in a provider, and how to implement enrichment effectively in production systems.
What Is Transaction Enrichment and Why Does It Matter
Transaction enrichment is the process of converting raw financial transaction records into structured, contextualized data. A single raw transaction string might contain fragments of a merchant name, a location abbreviation, a payment processor identifier, and a reference number, all compressed into a short, poorly formatted text field. Transaction enrichment disentangles these elements and maps them to real-world entities.
A fully enriched transaction typically includes a clean merchant name, a spending category, the merchant's logo and brand colors, a physical or web location, the payment channel used, whether the transaction is recurring, and a confidence score indicating how reliable the enrichment is.
This process is also called bank transaction enrichment, merchant data enrichment, financial data enrichment, or transaction data enrichment depending on the context.
The reason transaction enrichment matters so much is that virtually every user-facing feature in a financial product depends on it. Budgeting tools need accurate categories. Subscription management needs recurring payment detection. Spending analytics needs merchant identification. Fraud detection needs geographic and channel context. Without reliable enrichment upstream, every downstream feature degrades.
Why Raw Bank Transaction Data Is Broken
Financial transaction data was designed for settlement and reconciliation between banks, not for consumer-facing applications. Several structural factors make raw data unreliable without additional processing.
Every bank uses its own encoding rules and legacy systems, producing different formats for the same merchant. Payment intermediaries like card networks, acquirers, payment facilitators, and digital wallets each inject their own identifiers and abbreviations into the transaction string. Merchant names are frequently truncated due to character limits in legacy banking infrastructure. The same merchant appears differently across countries due to localization, language differences, and regional payment conventions. There is no universal merchant identifier shared across banks or payment networks.
These are not bugs that banks will fix. They are structural artifacts of a global payment system built over decades by thousands of independent institutions. Any fintech product that displays transaction data to users must deal with this reality.
Consider what a single Starbucks transaction might look like across different banks and countries: STARBUCKS #12345 SEATTLE WA, SBX*STARBUCKS MOBILE ORDER, STARBUCKS COFFEE 0012345, or CARD PURCHASE STARBUCKS. Each of these refers to the same brand, but a naive string-matching system would struggle to reliably identify all of them.
A transaction enrichment API resolves all of these to the same merchant. For example, sending a raw Starbucks descriptor through the API:
{ "title": "SBX*STARBUCKS MOBILE ORDER", "country": "US", "type": "expense" }Returns a structured result regardless of the original format:
{ "merchant": { "name": "Starbucks", "logo": "https://logos.triqai.com/images/starbuckscom" }, "category": { "primary": "Food and Drink", "secondary": "Coffee and Cafes" }, "channel": "mobile_app", "confidence": 0.98}How a Transaction Enrichment API Works
A modern transaction enrichment API processes raw transaction data through multiple stages to produce structured output. Understanding this pipeline helps developers evaluate providers and debug quality issues.
The first stage is normalization. The raw transaction string is cleaned by removing noise tokens, standardizing character encoding, normalizing separators, and converting to a consistent format. This addresses the most surface-level inconsistencies in bank data.
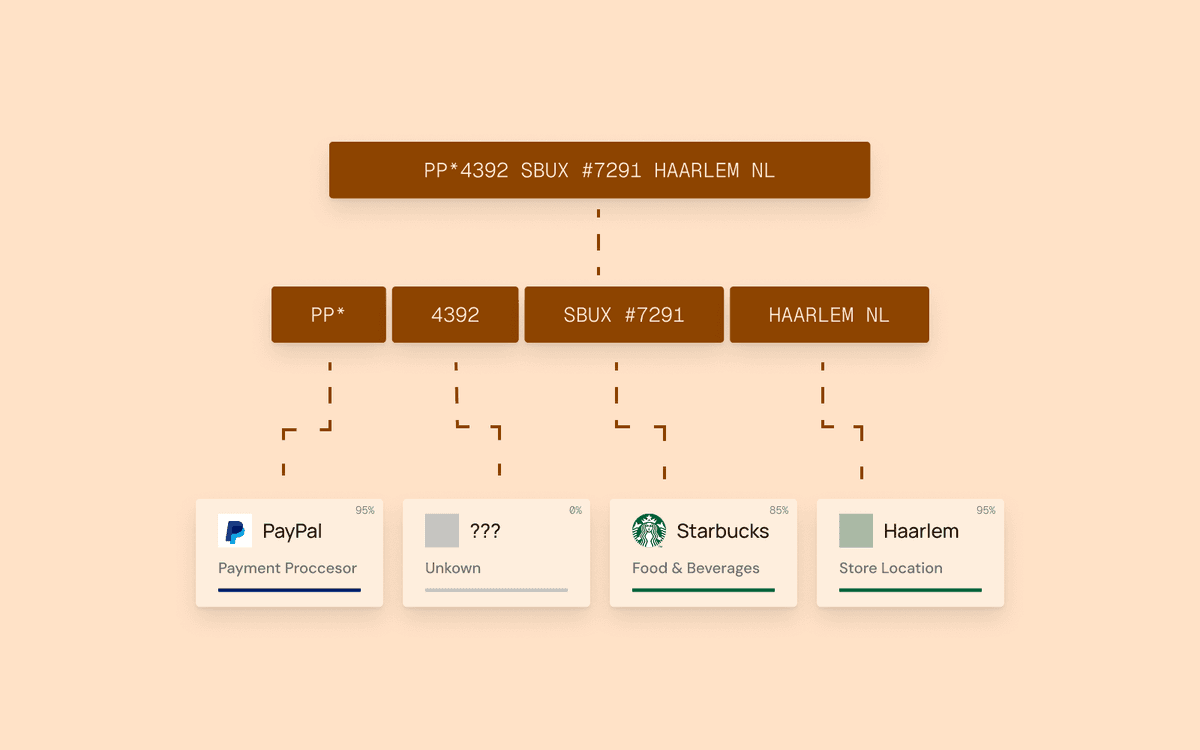
The second stage is parsing. The normalized string is analyzed to extract potential components: merchant name fragments, location data, payment processor identifiers, reference numbers, and date artifacts. This is where the system begins separating signal from noise.
The third stage is merchant resolution. Parsed fragments are matched against real-world merchant entities. This is the most complex step, because it requires handling abbreviations, alternate names, franchise variations, and marketplace sellers. Advanced APIs like Triqai's enrichment engine use AI reasoning combined with real-time web-derived context to identify merchants dynamically, even those that have never been seen before, without relying on a fixed merchant database.
The fourth stage is categorization. Each transaction is classified into a spending category using a combination of merchant identity, MCC codes, transaction context, and learned patterns. Strong categorization systems support hierarchical categories (primary, secondary, and tertiary levels) and separate income from expense transactions. For a deep dive into implementing categorization effectively, see our guide on automated transaction categorization best practices.
The fifth stage is metadata enrichment. Additional context is attached to the transaction: merchant logos, brand colors, website URLs, geographic location data including coordinates and structured addresses, and payment channel identification.
The final stage is confidence scoring. The API assigns a confidence score indicating how reliable each element of the enrichment is. This allows downstream systems to make informed decisions about whether to display enriched data directly or fall back to a safer representation.
Most providers expose this entire pipeline through a REST API that accepts raw transaction data (usually as JSON) and returns a structured enrichment response. Some, like Triqai, also offer official SDKs (such as the Node.js SDK) for an even smoother developer experience with built-in retries, typed responses, and auto-pagination.
What a Transaction Enrichment API Returns
The quality and depth of API responses vary significantly between providers. A comprehensive transaction enrichment API response should include several distinct data categories.
For merchant identification, expect a clean merchant name, the original descriptor preserved for reference, a merchant logo URL, brand colors, the merchant's website, and a unique merchant identifier for deduplication. Triqai, for example, uses AI reasoning and web-derived context to identify merchants globally, returning clean names, logos, and structured metadata regardless of whether the merchant appears in any traditional database. Our dedicated guide on how to enrich raw transaction data with clean merchant names walks through the merchant identification step in depth, including long-tail coverage and the intermediary-versus-merchant problem.
For transaction categorization, the response should include a primary category, and ideally secondary and tertiary categories for granularity. Triqai supports 121 distinct categories spanning 38 income categories and 69 expense categories, with hierarchical depth up to three levels.
For location data, look for structured address components (street, city, state, postal code, country), geographic coordinates, and timezone information. The best providers offer store-level location precision across millions of places globally.
For payment context, the response should identify the payment channel (in-store, online, mobile app, ATM, bank transfer) and detect payment intermediaries (Square, Stripe, PayPal) separately from the underlying merchant.
For confidence scoring, each enrichment field should include a confidence indicator. This is essential for production systems because it allows your application to treat high-confidence and low-confidence enrichments differently.
Build vs Buy: Why Most Teams Choose an API
The decision to build transaction enrichment in-house versus using a third-party API is one of the most consequential infrastructure choices a fintech team makes. While building in-house offers maximum control, the practical challenges are substantial.
Building an effective enrichment system requires either assembling and maintaining a massive merchant dataset that inevitably falls behind reality, or building AI infrastructure that can reason about transactions using web data and contextual signals. Either path demands training and maintaining machine learning models that can handle the extreme diversity of bank transaction formats across countries and institutions. It requires dedicated data engineering to gather and process merchant context. It requires infrastructure to serve enrichment at production scale with sub-second latency. And it requires ongoing engineering investment to handle new edge cases, payment methods, and geographies as they emerge.
Industry experience consistently shows that building transaction enrichment from scratch takes six to twelve months and hundreds of thousands of dollars before reaching a level of accuracy that a specialized API provides from day one. Even companies that initially build in-house frequently switch to external providers once they encounter the long-tail problem: the top 500 merchants might cover half of all transactions, but accurately enriching the other half requires handling millions of smaller, regional, and emerging businesses.
Using a transaction enrichment API lets teams ship enrichment-dependent features in days instead of months, access continuously improving models without internal ML expertise, benefit from the provider's aggregate data across all their customers, and focus engineering resources on building product features rather than data infrastructure. For a detailed analysis of costs, timelines, and a decision framework, read our dedicated guide on whether to build or buy transaction enrichment.
How to Evaluate a Transaction Enrichment API Provider
Not all enrichment APIs deliver the same quality. When evaluating providers, go beyond published accuracy benchmarks and test against the specific data patterns your product encounters.
Start by testing on your actual data. Request a trial and run your production transaction feed through the API. Measure the merchant recognition rate, categorization accuracy, and the percentage of transactions returned as "unknown." Published benchmarks are typically measured on curated datasets biased toward well-known merchants, which overstates real-world performance.
Evaluate geographic and payment type coverage. If your product operates internationally, test how the API handles local banks, regional payment processors, non-Latin scripts (Japanese, Korean, Arabic, Cyrillic), and local payment methods (PIX, UPI, iDEAL, SEPA). Many providers are optimized for North American transactions and underperform elsewhere.
Examine the response structure and metadata depth. A good provider returns more than just a name and category. Look for hierarchical categories, merchant logos, location data with coordinates, payment channel identification, intermediary detection, and confidence scores for every field.
Test latency and throughput under realistic conditions. For real-time feeds, enrichment should complete in under two seconds. For batch processing, verify the API supports bulk endpoints and can handle your volume without rate-limiting issues.
Verify data privacy and compliance practices. Financial transaction data is sensitive. Confirm the provider is GDPR-compliant, does not retain raw transaction data beyond processing, and provides clear documentation about data handling.
| Evaluation criteria | What to test | Why it matters |
|---|---|---|
| Accuracy on your data | Run real production transactions through the API | Published benchmarks overstate real-world performance |
| Geographic coverage | Test local banks, non-Latin scripts, regional payment methods | Many APIs underperform outside North America and Western Europe |
| Response depth | Check for categories, logos, location, confidence scores | Shallow responses limit downstream features |
| Latency | Measure p50 and p95 response times under load | Slow enrichment blocks real-time transaction feeds |
| Compliance | Verify GDPR, data retention, and handling policies | Financial data requires strict privacy controls |
How Triqai's Transaction Enrichment API Works
Triqai takes a fundamentally different approach to transaction enrichment. Rather than relying on a fixed merchant dataset, Triqai combines AI-powered reasoning with real-time web context to identify merchants, categorize transactions, and resolve locations globally. This flexible architecture means Triqai can handle millions of merchants and entities dynamically, reasoning about each transaction with full context before returning a result.
When a transaction is sent to Triqai's API, the system analyzes the raw descriptor alongside contextual signals including the transaction amount, currency, country of origin, and transaction type. It then uses AI reasoning to identify the most likely merchant, drawing on real-time web context from business directories, map services, delivery platforms, and social profiles. This approach means Triqai is not limited to a fixed merchant list. It can identify millions of merchants and entities dynamically, including new, small, and regional businesses that no static database would cover.
Because Triqai reasons about each transaction using web data and contextual signals rather than relying on a single static dataset, it avoids the false positives and blind spots that plague fixed-database systems. The system detects payment processors and intermediaries, achieves 95%+ accuracy on transaction categorization across 121 distinct categories, and provides store-level location enrichment across 150+ countries.
A critical differentiator is how Triqai handles payment intermediaries. When a transaction passes through a processor like Square, Stripe, or PayPal, many enrichment systems identify the intermediary but miss the underlying merchant. Triqai separates these entities by reasoning through the full payment chain, identifying both the payment facilitator and the actual business the consumer paid, each with their own name, logo, and metadata. This contextual reasoning approach means Triqai considers more information before returning a result, reducing false matches and providing reliable answers even for complex payment flows.
The API is designed for simplicity. With the official Node.js SDK, enrichment takes just a few lines:
import Triqai from "triqai";const triqai = new Triqai("triq_your_api_key");const result = await triqai.transactions.enrich({ title: "SQ *VERVE COFFEE ROASTERS SAN FRAN", country: "US", type: "expense",});Or use the REST API directly with a single POST request:
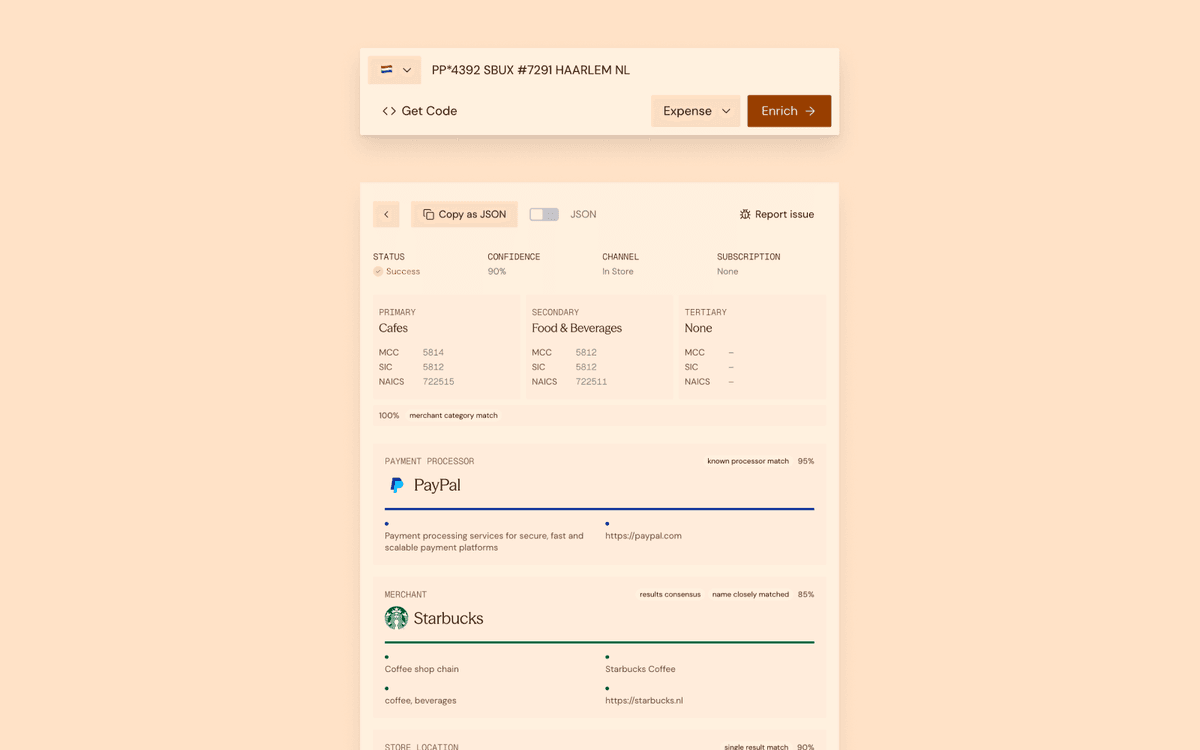
curl -X POST https://api.triqai.com/v1/transactions/enrich \ -H "Authorization: Bearer YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "title": "SQ *VERVE COFFEE ROASTERS SAN FRAN", "country": "US", "type": "expense" }'The response includes merchant identity, category hierarchy, location data, intermediary detection, and confidence scores:
{ "merchant": { "name": "Verve Coffee Roasters", "logo": "https://logos.triqai.com/images/verve-coffeecom", "website": "https://www.vervecoffee.com" }, "category": { "primary": "Food and Drink", "secondary": "Coffee and Cafes", "tertiary": "Coffee Shop" }, "location": { "city": "San Francisco", "state": "CA", "country": "US", "formatted": "San Francisco, CA, United States" }, "intermediary": { "name": "Square", "type": "payment_facilitator" }, "type": "expense", "channel": "in_store", "confidence": 0.96}There is no complex setup, no batch file uploads, and no delayed processing. Results are available in real-time.
Triqai offers a free tier with 100 enrichments per month, making it easy for developers to test and prototype before committing. Paid plans start at 21 euros per month for 4,000 enrichments with transparent per-transaction overage pricing.
Common Edge Cases Every Enrichment API Must Handle
Even the best transaction enrichment API encounters difficult cases. Understanding these edge cases helps developers design resilient systems.
Generic descriptors like POS PAYMENT, CARD PURCHASE, or DIRECT DEBIT contain no merchant signal at all. These transactions cannot be reliably enriched by any system, and the API should return a low confidence score rather than guessing incorrectly.
Marketplace transactions from platforms like Amazon, eBay, or Etsy obscure the underlying seller. The transaction descriptor might show the platform name, but the actual purchase could fall into any number of categories.
Digital wallet transactions through Apple Pay, Google Pay, or Samsung Pay add an abstraction layer that reduces the merchant information available in the bank feed. This is a structural challenge that requires specialized handling.
Subscription transactions from services that bill through intermediary payment entities may show the payment processor name rather than the service name, making identification difficult without historical context.
International transactions with non-Latin scripts, local abbreviations, or region-specific formatting patterns require multilingual processing capabilities that many providers lack.
The mark of a good enrichment API is not perfect accuracy on every transaction. That is structurally impossible. It is consistent accuracy on the vast majority of transactions, combined with honest confidence scoring that lets your application handle uncertain cases gracefully.
Best Practices for Production Transaction Enrichment
When implementing a transaction enrichment API in production, several practices help maintain data quality and system reliability.
Always store both raw and enriched data. Raw data enables re-enrichment as the API's models improve, simplifies debugging, and satisfies compliance requirements that may mandate retention of source records.
Respect confidence scores in your UI and business logic. Do not display a merchant name with the same certainty whether the confidence is 95% or 55%. Design fallback presentations for low-confidence enrichments that show the original descriptor rather than a potentially wrong merchant name.
Never overwrite user corrections with automated enrichment. If a user manually recategorizes a transaction, that correction should persist even when re-enrichment runs. User trust depends on the application respecting their input.
Design for re-enrichment from the start. Enrichment models improve over time, and transactions that were poorly enriched six months ago may resolve correctly today. Build your data architecture to support periodic re-enrichment of historical transactions.
Cache enrichment results for repeated merchant descriptors. The same descriptor string (like STARBUCKS #12345) typically resolves to the same merchant every time. A simple descriptor-level cache dramatically reduces API calls:
import hashlib, json, rediscache = redis.Redis()CACHE_TTL = 48 * 3600 # 48 hoursdef enrich_with_cache(description, country, tx_type): cache_key = f"enrich:{hashlib.md5(f'{description}:{country}'.encode()).hexdigest()}" cached = cache.get(cache_key) if cached: return json.loads(cached) result = call_enrichment_api(description, country, tx_type) if result: cache.setex(cache_key, CACHE_TTL, json.dumps(result)) return resultA TTL of 24 to 72 hours balances freshness against efficiency.
Filter transactions that do not benefit from enrichment before sending them to the API. Internal transfers, ATM withdrawals, bank fees, and interest payments generally do not have a meaningful merchant to identify. Excluding them reduces costs and avoids noise in your enriched data.
Transaction Enrichment Use Cases Across Fintech
Transaction enrichment powers a wide range of fintech features and products, making it one of the most versatile infrastructure investments a team can make.
Personal finance and budgeting apps use enrichment to display clean transaction feeds, automated spending categories, and budget tracking. Without accurate merchant identification and categorization, budgeting features produce misleading results that erode user trust.
Accounting and expense management platforms use enrichment to automatically categorize business expenses, match receipts to transactions, and generate accurate financial reports. Enrichment eliminates the manual data entry that makes expense management tedious.
Banking and neobanking apps use enrichment to present professional transaction feeds with merchant logos and clean names, offer spending insights, and power personalized financial advice. Transaction enrichment is what separates a modern banking experience from a legacy statement view. For a deeper look at how banks specifically use enrichment to reduce chargebacks, cut support costs, and meet PSD3 requirements, see our guide on transaction enrichment for banks.
Lending and credit assessment platforms use enriched transaction data to analyze borrower spending patterns, verify income sources, assess creditworthiness, and detect financial risk signals. Accurate categorization and merchant identification enable more precise and fair lending decisions.
Fraud detection and compliance systems use enrichment to identify suspicious transaction patterns, flag transactions with known high-risk merchants, and support anti-money laundering monitoring. The geographic and merchant context that enrichment provides is critical for effective fraud models.

Conclusion
A transaction enrichment API is foundational infrastructure for any serious fintech product. It transforms the broken, inconsistent data that banks produce into the structured, reliable information that powers accurate analytics, trustworthy user interfaces, and intelligent features.
The problem is inherently complex. Raw bank data was never designed for consumer applications, merchants appear differently across every bank and country, and perfect accuracy on every transaction is structurally impossible. But well-designed enrichment APIs like Triqai make this complexity manageable by handling the parsing, matching, categorization, and scoring behind a simple API interface.
For fintech developers, the choice is clear: invest months and hundreds of thousands of dollars building enrichment in-house, or integrate a proven API and start shipping enrichment-dependent features in days. For JavaScript and Node.js projects, install the official SDK with npm install triqai to get started in minutes with full TypeScript support and automatic retries. Your users will never see the enrichment pipeline directly, but they will notice the difference between an app that understands their transactions and one that does not.
Frequently asked questions
Tags
Related articles

Written by
Wes Dieleman
Founder & CEO at Triqai
December 20, 2025
Wes founded Triqai to make transaction enrichment accessible to every developer and fintech team. With a background in software engineering and financial data systems, he leads Triqai's product vision, AI enrichment research, and API architecture. He writes about transaction data, merchant identification, and building developer-first fintech infrastructure.